 About me
About me



Abstract
This paper addresses the gap between the growing enthusiasm for Multi-Agent Systems (MAS) and their minimal performance gains compared to single-agent frameworks. It presents a comprehensive study of the challenges hindering MAS effectiveness. The study identifies and categorizes the failure modes in MAS, and it proposes a taxonomy to analyze MAS failures.
Key takeaways
- The correctness of state-of-the-art open-source MAS can be as low as 25%.
- A taxonomy of 14 distinct failure modes in MAS, categorized into 3 primary failure categories:
- specification and system design failures: arising from deficiencies in the design of the system architecture, poor conversation management, unclear task specifications or violation of constraints, and inadequate definition or adherence to the roles and responsibilities of the agents.
- inter-agent misalignment: arising from ineffective communication, poor collaboration, conflicting behaviors among agents, and gradual derailment from the initial task.
- task verification and termination: resulting from premature execution termination, as well as insufficient mechanisms to guarantee the accuracy, completeness, and reliability of interactions, decisions, and outcomes.
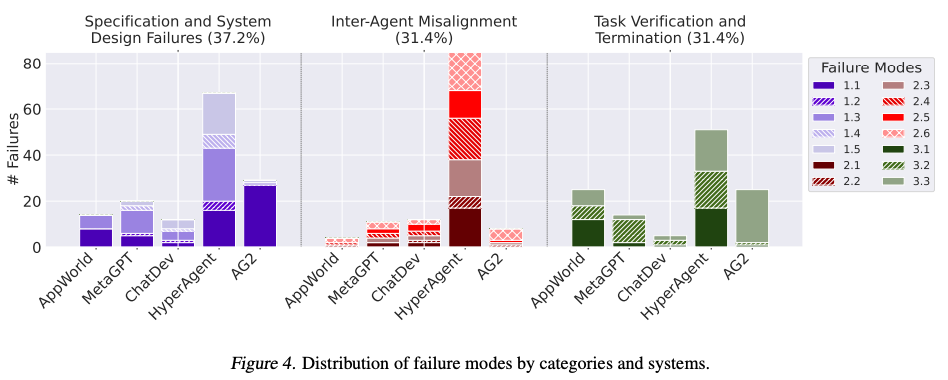
- No single failure category disproportionately dominates.
- Failures in MAS are not isolated events and can have a cascading effect that influences other failure categories.
- Many MAS failures arise from challenges in inter-agent interactions rather than the limitations of individual agents.
- Simple prompt engineering and enhanced agent topological orchestration do not resolve all failure cases.
- MASs failure modes align with common failure modes observed in complex human organizations.
Experiment
Preliminary concepts
Because the definition of agents is not a resolved debate, in this paper it means an artificial entity with prompt specifications (initial state), conversation trace (state), and the ability to interact with environments, such as tool usage (action).
A multi-agent system (MAS) is then defined as a collection of agents designed to interact through orchestration, enabling collective intelligence.
Objectives
The primary objectives of the study are:
- To conduct a systematic evaluation of MAS execution traces to understand MAS failure modes.
- To identify and categorize the failure modes in taxonomy (MASFT).
- To develop a scalable LLM-as-a-judge pipeline for automated evaluation of MAS performance and failure mode diagnosis.
- To explore the potential of improved specification and prompting strategies in mitigating MAS failures.
Setup
-
Models:
- Five popular open-source MAS frameworks:
- MetaGPT simulates Standard Operating Procedures (SOPs) of different roles in software companies to create open-ended software applications.
- ChatDev simulates different software engineering phases like design, code, and QA through simulated roles in a software engineering company.
- HyperAgent simulates a software engineering team with a central Planner agent coordinating with specialized child agents (Navigator, Editor, and Executor).
- AppWorld uses tool-calling agents specialized to utility services (e.g., GMail, Spotify) being orchestrated by a supervisor to achieve cross-service tasks.
- AG2 is an open-source programming framework for building agents and managing their interactions.
- The LLM-as-a-judge pipeline uses OpenAI’s o1 model.
- Five popular open-source MAS frameworks:
-
Datasets:
- The analysis is based on over 150 conversation traces.
- Each trace averages over 15,000 lines of text.
-
Metrics:
- Cohen’s Kappa score: used to measure inter-annotators reliability. The annotators are the human experts and the LLM annotator.
- Accuracy, Recall, Precision, and F1 score: used to evaluate the performance of the LLM annotator.
Grounded Theory approach to construct MASFT directly from empirical data rather than testing predefined hypotheses:
- sampling of MASs based on variations in their objectives, organizational structures, implementation methodologies, and underlying agent personas.
- chose tasks to represent the intended capabilities of the MAS rather than artificially challenging scenarios.
- open coding to analyze the traces collected for agent–agent and agent–environment interactions: breaks qualitative data into labeled segments, allowing annotators to create new codes and document observations through memos.
- iterative, constant comparative analysis of new codes created with existing ones.
- reach theoretical saturation, the point at which no new insights emerged from additional data.
Inter-annotator agreement study to validate the MASFT:
- round 1, sample 5 different MAS traces from over 150 traces & three annotators annotate these traces using the failure modes and definitions in the initial taxonomy: Cohen’s Kappa score of 0.24.
- annotators work on the taxonomy to refine it: iteratively changing the taxonomy until converging to a consensus regarding whether each and every failure mode existed or not in all 5 of the collected traces.
- round 2, sample another set of 5 traces, each from a different MAS: Cohen’s Kappa score of 0.92. The taxonomy is left untouched given the nearly-perfect score.
- round 3, sample another set of 5 traces, each from a different MAS: Cohen’s Kappa score of 0.84.
Validate the LLM-as-a-judge pipeline on the annotated traces of round 3.
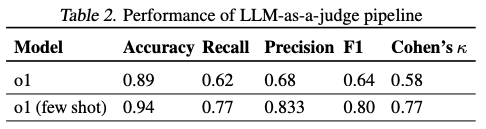
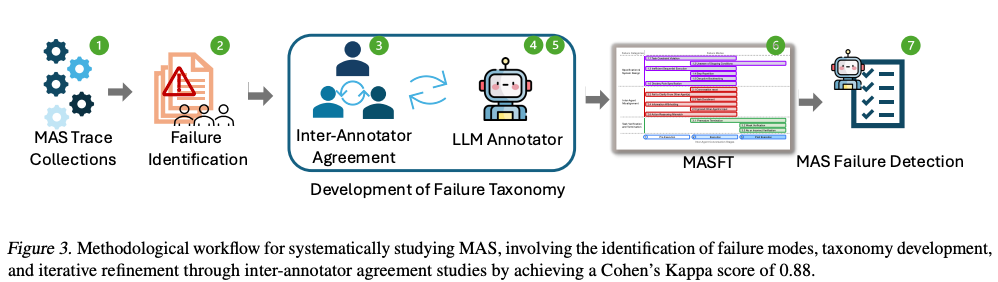
Results
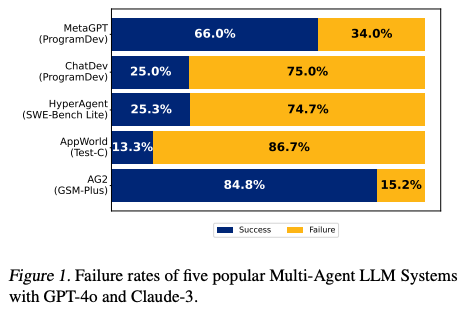
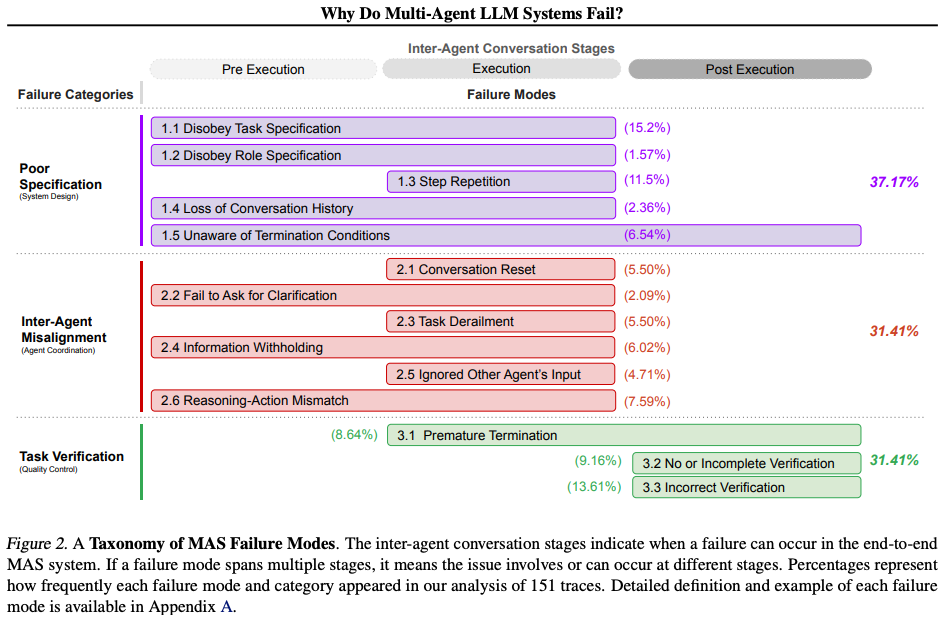
Discussions
-
Strengths:
- The scalable LLM-as-a-judge evaluation pipeline for analyzing MAS performance and diagnosing failure modes.
-
Attention points:
- LLM-as-a-judge evaluation pipeline has been validated against three human expert annotations on 10 traces.
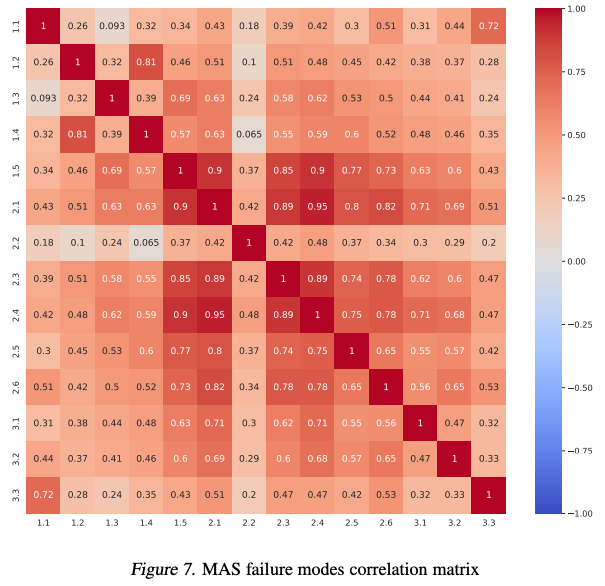
- Some MASs failure modes remains highly correlated.