About me
About me



Abstract
The research addresses the significant computational resources required by Large Vision-Language Models (VLMs), which limits their use on mobile and edge devices. Current smaller VLMs often adopt design choices from larger counterparts, like extensive image tokenization, leading to inefficient GPU memory use and reduced practicality for on-device applications. This study introduces SmolVLM, a series of compact multimodal models engineered for resource-efficient inference. The paper’s scope involves a systematic exploration of architectural configurations, tokenization strategies, and data curation methods optimized for low computational demands. The primary focus is to identify key design choices that enhance performance on image and video tasks while maintaining minimal memory footprints.
Key takeaways
Regarding compact VLMs architecture:
- Careful architectural design can substantially reduce resource requirements of models without sacrificing capability.
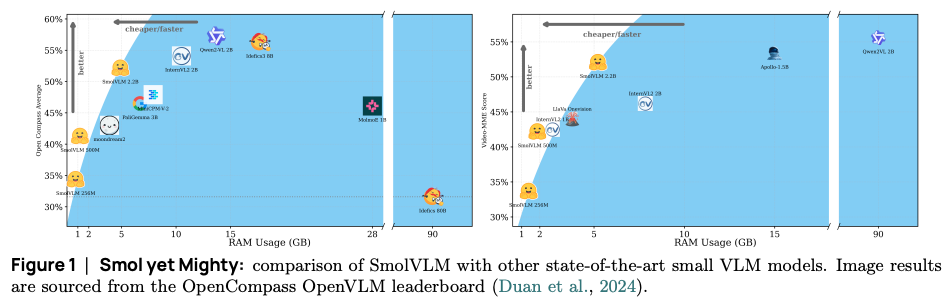
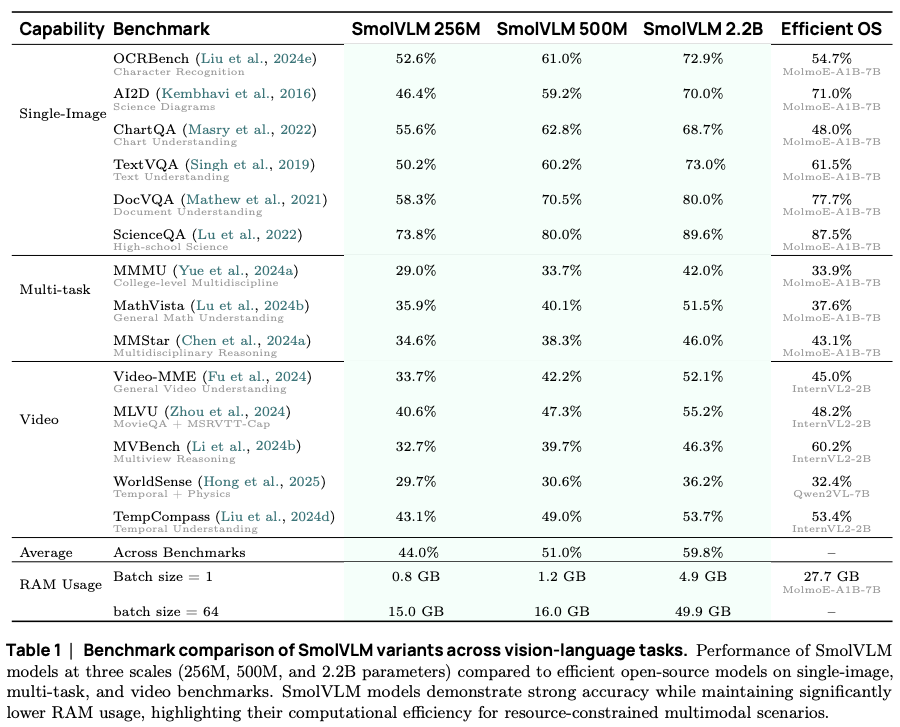
- The smallest SmolVLM model (SmolVLM-256M) operates with less than 1GB of GPU RAM during inference.
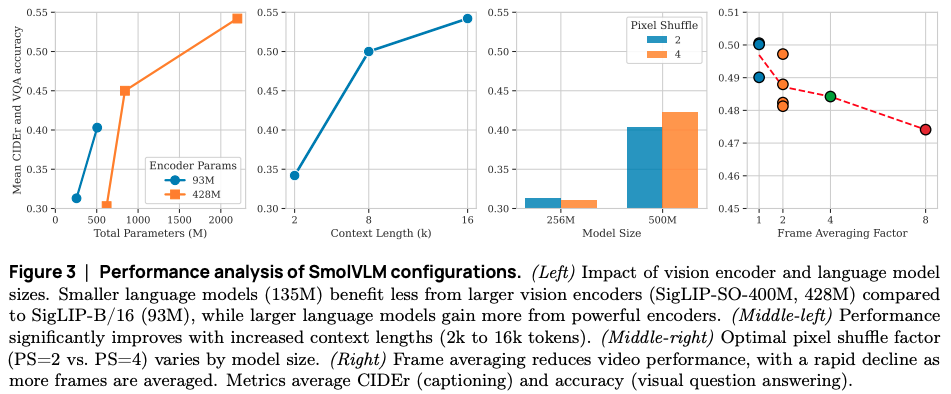
- A balanced allocation of parameters between the vision encoder and the language model is beneficial.
- Extending context length enables higher image resolutions at minimal overhead.
Regarding tokenizers for compact VLMs :
- Benefit from more aggressive visual token compression.
- Image splitting enhances performance for vision tasks, while video frame averaging does not.
- Learned positional tokens outperform raw text tokens.
- System prompts and media intro/outro tokens significantly improve performance, particularly for video tasks.
Regarding training for compact VLMs:
- During Supervised Fine-Tuning (SFT), it is better to only train on completions.
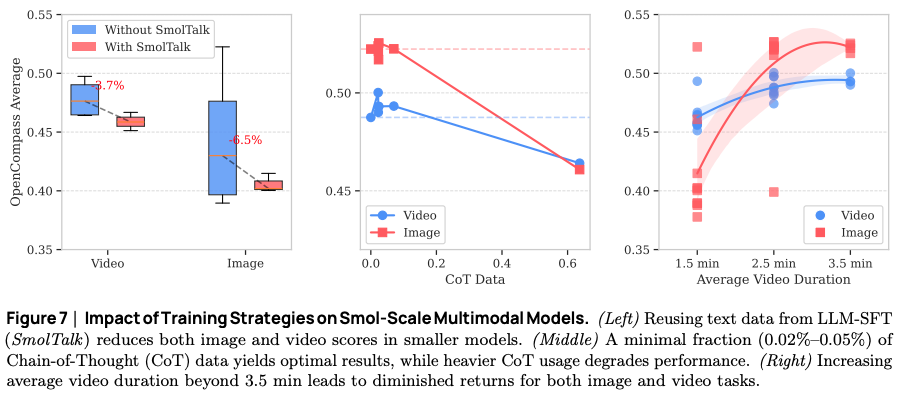
- Adding text from the SFT blend of an LLM proved less effective than new text SFT data.
- Excessive Chain-of-Thought (CoT) data can harm the performance.
- Moderately increasing video duration during training improves both video and image task performance.
Experiment
Preliminary concepts
-
Vision Language Models: VLMs utilize vision encoders to generate ‘vision tokens’ that are then fed into a LM.
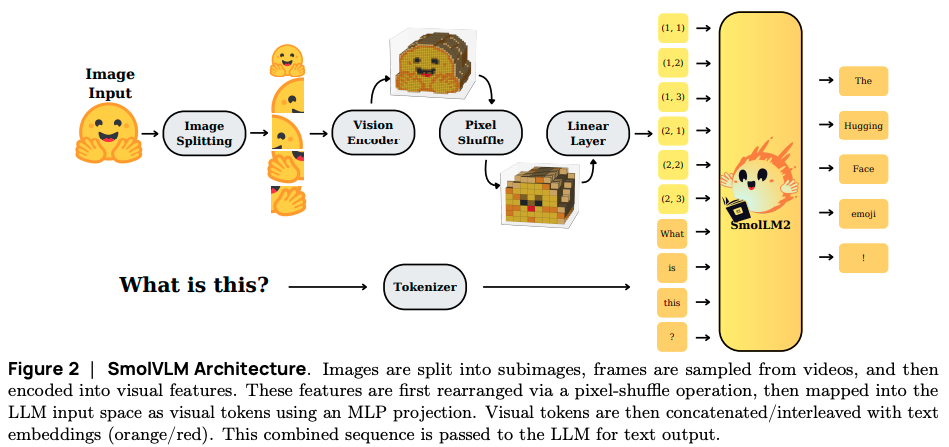
-
Rotary Position Embedding (RoPE): RoPE is a type of position embedding which encodes absolute positional information with rotation matrix and naturally incorporates explicit relative position dependency in self-attention formulation. Notably, RoPE comes with valuable properties such as flexibility of being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and capability of equipping the linear self-attention with relative position encoding.
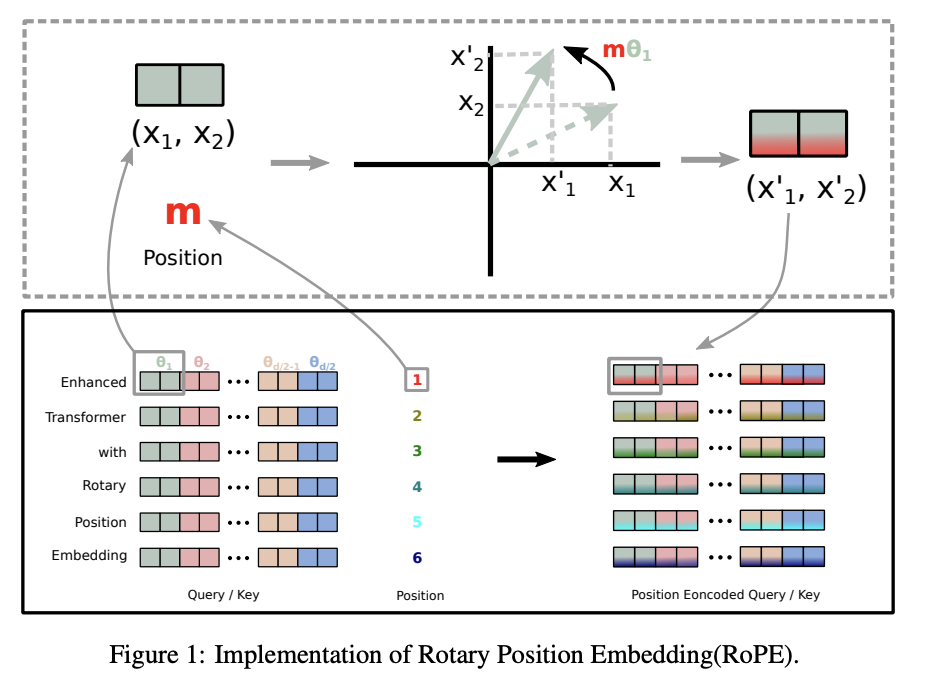
-
Pixel Shuffle (space-to-depth): pixel shuffle is a token compression technique that rearranges spatial features into additional channels, reducing spatial resolution but increasing representational density. This reduces the total number of visual tokens by a factor of , where is the shuffle ratio.

-
Learned tokens vs. String tokens: string tokens: use simple string tokens (e.g.,
<row_1_col_1>) to encode split sub-image positions. learned tokens: each position is represented by a vector, and these vectors are learned during training, similar to how word embeddings are learned for text.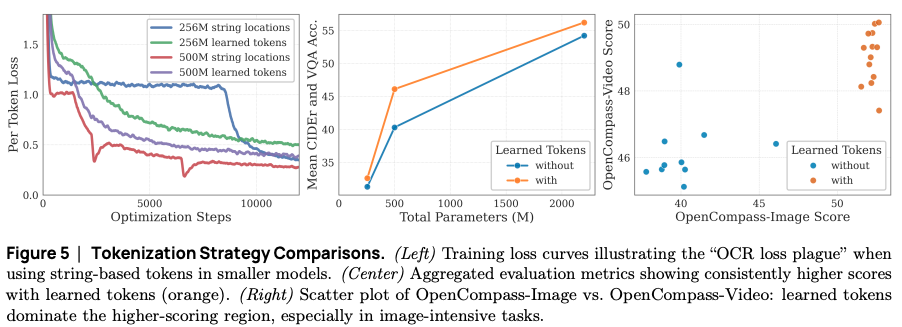
-
VLMEvalKit: standardized generation-based evaluation methodology, assessing Large Vision-Language Models (LVLMs) based on the textual output they generate in response to multi-modal inputs. Performance is quantified using two primary techniques:
- Exact Matching (EM), which performs direct string comparison against ground truth for high objectivity but low flexibility.
- LLM-based Answer Extraction, which uses a separate “Judge” LLM to assess semantic correctness, offering more flexibility but introducing dependency on the Judge model’s capabilities and configuration.
Objectives
The primary objectives of the experiment are:
-
To systematically explore the impact of various architectural choices, including:
- the balance of parameters between the vision encoder and the language model
- tokenization methods
- positional encoding
- the composition of training data
-
To validate that SmolVLM models can generalize effectively to video understanding tasks, highlighting their suitability for diverse, real-time, on-device multimodal applications.
-
To compare the performance and efficiency (specifically GPU RAM usage) of SmolVLM models against other state-of-the-art VLMs, including much larger ones.
Setup
-
Models:
- The SmolVLM family:
- SmolVLM-256M: 93M SigLIP-B/16 encoder + SmolLM2-135M + 8k-token context.
- SmolVLM-500M: 93M SigLIP-B/16 encoder + SmolLM2-360M + 8k-token context.
- SmolVLM-2.2B: 400M SigLIP-SO400M encoder + SmolLM2 1.7B-parameter + 16k-token context.
- Encoder-LM Parameter Balance: Three SmolLM2 variants (135M, 360M, 1.7B parameters) X two SigLIP encoders: SigLIP-B/16 (93M) and SigLIP-SO400M (428M).
- Extended context length by increasing the RoPE base from 10k to 273k.
- The SmolVLM family:
-
Encoding & Tokenization:
- Image-splitting strategy where high-resolution images are divided into multiple sub-images along with a downsized original.
- Rescaled video frames to the image encoder’s resolution.
- Pixel Shuffle used for visual token compression, with shuffle ratios of r=2 and r=4.
- Learned positional tokens vs. string-based tokens for encoding sub-image positions.
-
Prompting:
- Prepend concise instructions to clarify task objectives and reduce ambiguity during zero-shot inference; e.g. conversational datasets utilize prompts like “You are a useful conversational assistant” whereas vision-focused tasks employ “You are a visual agent and should provide concise answers”.
- Media Intro/Outro tokens: surround media with textual markers*“Here is an image…”* or “Here are N frames sampled from a video…” then “Given this image/video…”.
- Masking user prompt: user-prompt masking during supervised fine-tuning as a way to forces models to rely on task-related content rather than superficial repetition, promoting better generalization.
Datasets:
-
long context data:
-
short context data:
- FineWebEdu
- DCLM
- math from SmolLM2
-
Chain-Of-Thought:
-
Vision:
- Docmatix
- MathWriting
- mixture balanced to emphasize visual and structured data interpretation while maintaining the focus on reasoning and problem-solving capabilities.
-
Video:
- LLaVA-video-178k (visual description and captioning)
- Video-STAR (visual description and captioning)
- Vript (visual description and captioning)
- ShareGPT4Video (visual description and captioning)
- Vista-400k (temporal understanding)
- MovieChat (narrative comprehension)
- FineVideo (narrative comprehension)
- M4-Instruct (multi-image data)
- Mammoth (multi-image data)
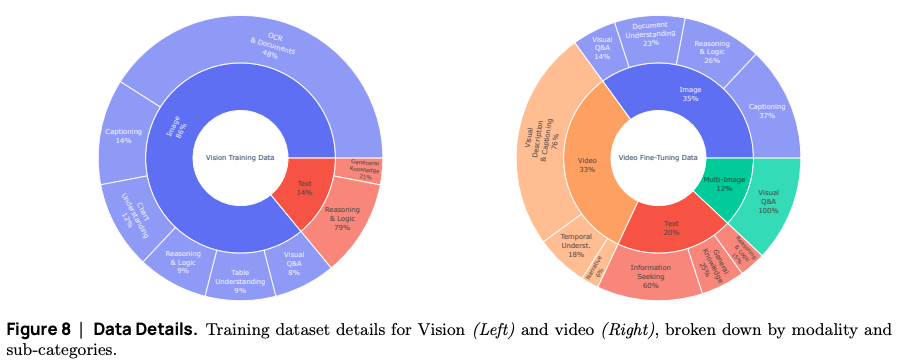
-
Metrics:
Results