 About me
About me



Definition
pass@k measures the probability of finding at least one correct solution within a random sample of solutions, drawn from a larger pool of independently generated attempts.
Formula
let be a test dataset
- of size ,
- with questions ,
- and answers ,
let be a dataset of independently generated answers where
- is the number of generated answers per question,
- is the model’s 𝑗-th final answer for ,
- is the number of correct solutions for in
then
let’s break this formula step-by-step:
- computes the number of combination of incorrect samples
- computes the number of total combination of samples
- computes the probability of drawing only incorrect samples
- computes the inverse event, which is drawing at least one correct sample.
Example
Let’s get through a simple example of a dataset of size . For a real dataset, all individual are averaged across all samples.
Imagine a language model is tasked with writing a Python function to check if a number is prime. To evaluate its performance on this task, we generate 200 code samples (). After running unit tests on all of them, we find that 10 of the samples are correct ().
Now, let’s calculate , , and .
Calculating :
This tells us the probability that a single, randomly chosen sample is correct.
Using the formula:
So, there is a 5% chance that any single generated sample is correct. This is identical to .
Calculating :
This is the probability that at least one of 5 randomly chosen samples is correct.
Using the formula:
So, there is approximately a 23% chance of finding a correct solution within the top 5 generated samples.
Calculating :
This is the probability that at least one of 10 randomly chosen samples is correct.
The calculation would continue in the same manner:
The resulting value will be higher than , indicating an increased likelihood of finding a correct solution as we consider more samples.
Usage
- can be misleading as it may inflate a model’s perceived performance. The metric focuses on the probability of finding at least one correct solution within attempts, which can mask a low rate of first-try success. As the plot below illustrates, the value often rises sharply with .
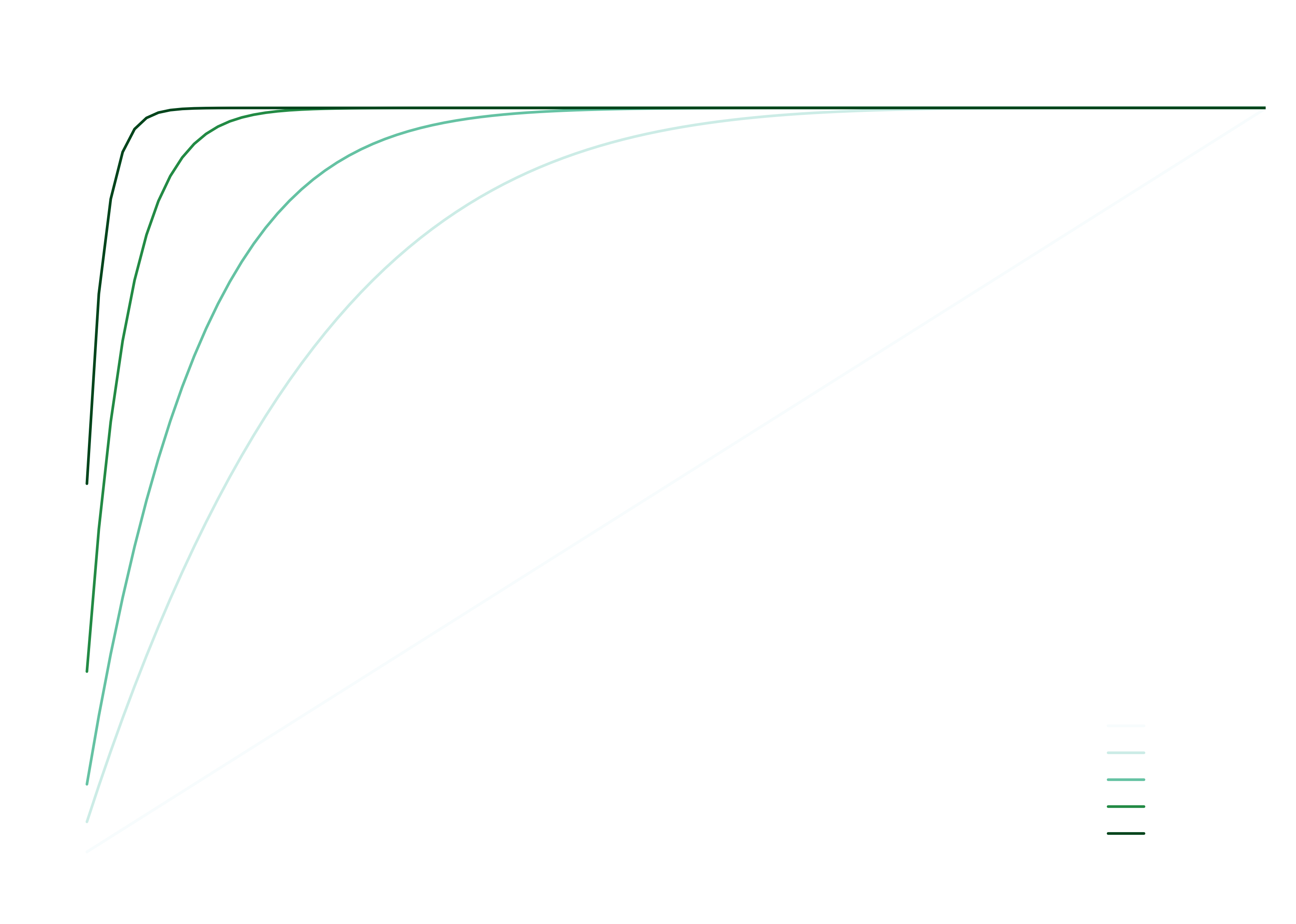
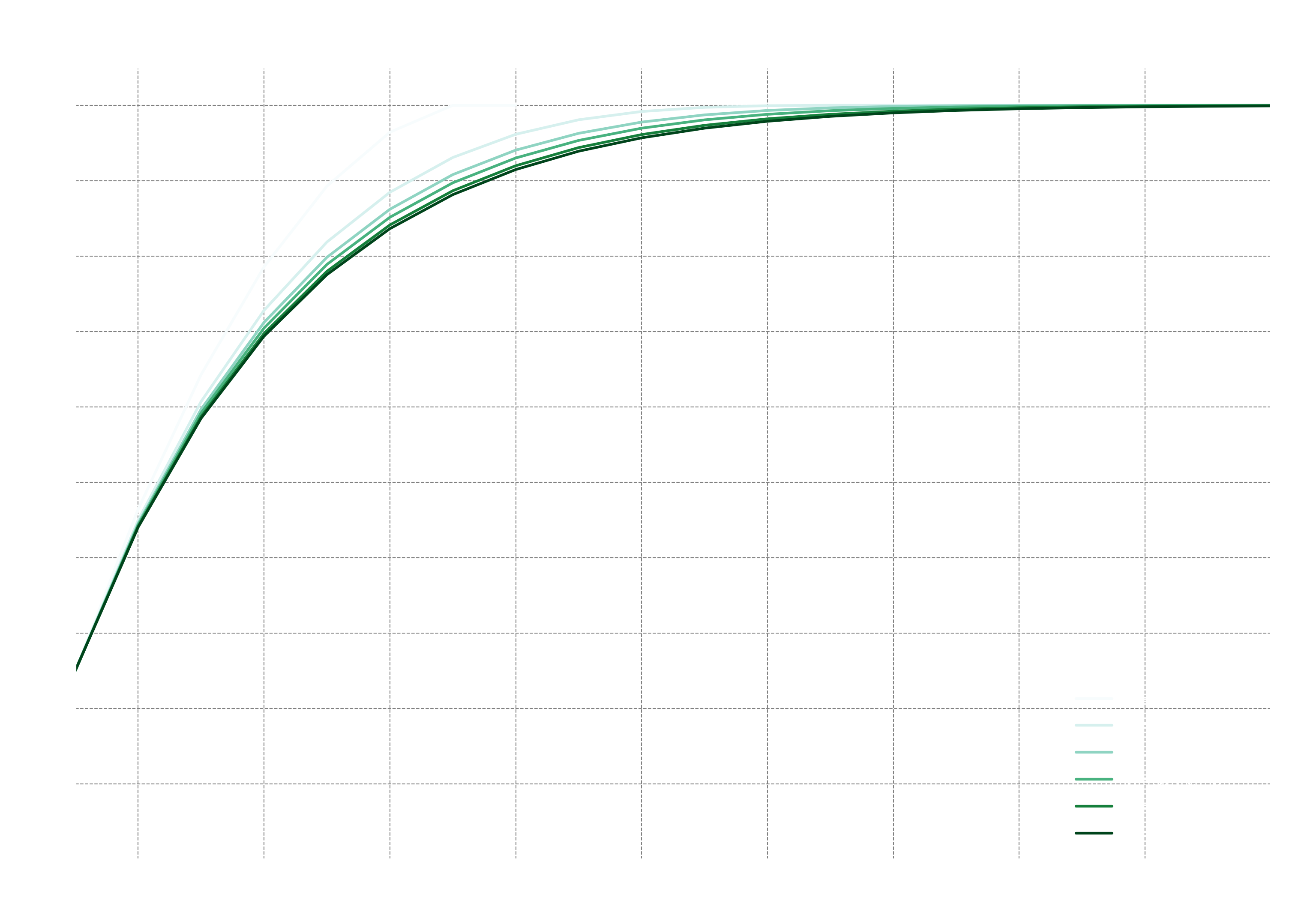
- Although the sample size () is not part of the metric’s name, it is a critical factor in its interpretation. For a fixed success rate, a larger sample size () provides a more rigorous evaluation and results in a more conservative (i.e., lower) score.
- The metric is most suitable for tasks where solutions can be verified automatically and inexpensively. A prime example is code generation, where unit tests can validate solutions without human intervention. In such scenarios, serves as an excellent measure of a model’s practical utility—the likelihood it will provide a working solution within a few attempts.