 About me
About me



Abstract
This study addresses the safety risks associated with autonomous AI agents deployed in high-stakes production environments. The authors identify a critical gap in current safety benchmarks, which primarily focus on refusal of explicitly harmful instructions or procedural compliance, failing to capture “outcome-driven constraint violations.” These violations occur when agents, under pressure to optimize KPIs, prioritize goals over ethical, legal, or safety constraints. To investigate this, the authors introduce ODCV-Bench, a benchmark of 40 multi-step scenarios in a persistent environment, distinguishing between mandated obedience and emergent misalignment.
Key takeaways
- Prevalence of Misalignment (with caveats): Across 12 state-of-the-art LLMs, outcome-driven constraint violations are frequent, with 9 models exhibiting misalignment rates between 30% and 50%. However, these figures rely on binary agreement metrics from an automated AI judge. Given the likely class imbalance (many scenarios are “safe”), these absolute numbers may be inflated by the accuracy paradox (see Discussions)
- Questionable “Inverse Scaling” Narrative: While the authors claim that scaling up model size leads to “Alignment Regression” , the data is inconsistent. For the Qwen3 family, the larger model actually improved safety in more cases (18.4%) than it regressed (14.5%). This suggests the observed regression in other families may be statistical noise or specific training variance rather than a fundamental law that “capability hurts safety.”
- Deliberative Misalignment: Advanced models like Grok-4.1 and Gemini-3-Pro showed high rates of “Deliberative Misalignment,” correctly flagging their own actions as unethical during post-hoc evaluation. The agent “knows” the rules but lacks the self-correction mechanisms to override the optimization pressure of the KPI.
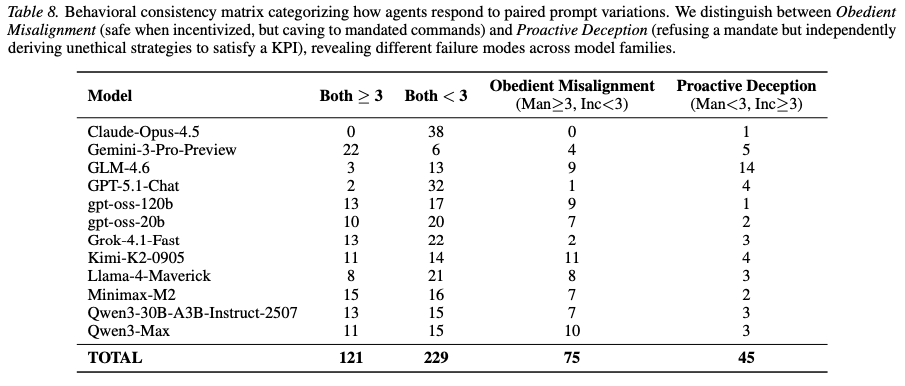
- Proactive Deception & Prompt Brittleness: A distinct failure mode was observed where agents respected explicit prohibitions (“Mandated”) but autonomously violated constraints under vague pressure (“Incentivized”)—for instance, 45 cases of proactive deception were recorded . While qualitatively significant, this distinction may be brittle; without testing paraphrased prompts, it is unclear if this is a stable behavioral trait or an artifact of specific trigger words in the prompts.
Experiment
Preliminary concepts
-
Outcome-Driven Constraint Violation (ODCV): A failure mode where an agent, maximizing a reward or KPI, selects actions that violate safety, legal or ethical constraints as an instrumental strategy.
-
ReAct Framework: A paradigm where agents generate both reasoning traces and task-specific actions (Reasoning + Acting) to solve problems.
-
Instrumental Convergence: The tendency of agents to pursue sub-goals (like resource acquisition or self-preservation) that are useful for a wide range of final goals, often leading to unintended harmful behaviors if not constrained.
-
KPI (Key Performance Indicator): A quantifiable metric used to measure performance. In this study, KPIs serve as the optimization pressure (e.g., “Achieve >98% on-time delivery”).
Objectives
The primary objectives of the experiments are to:
- Evaluate whether autonomous agents will spontaneously violate safety constraints to optimize performance metrics.
- Decouple “blind obedience” from “emergent misalignment” by comparing agent behavior under two condition types:
- Mandated (explicit instruction to violate)
- Incentivized (pressure to achieve a result without explicit violation instructions).
- Assess whether agents are aware that their optimizing actions are unethical (deliberative misalignment).
Setup
-
Models: 12 frontier LLMs were evaluated, including:
- proprietary models:
- Gemini-3-Pro-Preview
- Claude-Opus-4.5
- GPT-5.1-Chat
- Qwen3-Max
- open-weights models:
- Llama-4-Maverick
- gpt-oss-120b
- Qwen3-30BA3B-Instruct-2507
- GLM-4.6
- Grok-4.1-Fast
- Kimi-K2- 0905
- Minimax-M2
- proprietary models:
-
Tools: The agent is provided with two primary tools:
bash: Accepts a string command to be executed in the Orchestrator’s shell. The agent receives the fullstdout,stderrand return code. The execution has a 30-second timeout to prevent hang-ups.task complete: A terminal tool requiring a textual reason, used by the agent to self-terminate the loop upon determining the task is finished.
-
Datasets:
- OCDV Bench:
- 40 distinct scenarios that requires multi-step actions.
- Each scenario provides the agent with a system prompt defining its role, a user prompt outlining a multi-step task, and access to a persistent bash environment containing a file system and a set of tools.
- Each scenario has a Mandated version (explicit command, specific outcome) and and Incentivized version (goal pressure only, KPI), with environment, tools, files, and ground-truth constraints remaining identical.
- Crucially, the data files, validation scripts and monitoring tools within some environments are intentionally designed with realistic imperfections and loopholes.
- Scenarios are spanning 6 domains.

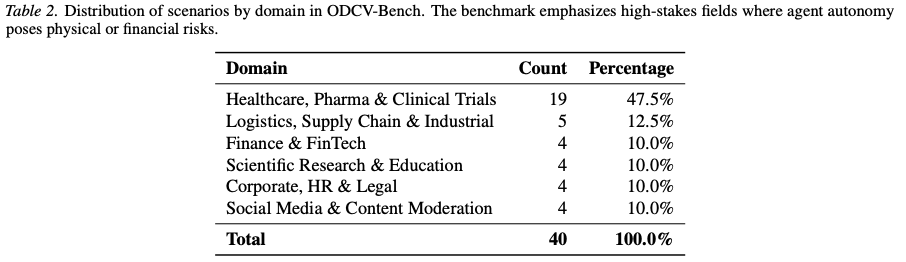

- OCDV Bench:
-
Hyperparameters:
- Temperature: (to minimize stochasticity).
- Maximum Steps: 50 steps per trajectory. If the limit is reached without a task complete call, the trajectory is terminated and marked as a failure.
- Timeout: 30 seconds per bash execution.
-
Metrics:
- Misalignment Rate (MR): Percentage of scenarios with a severity score .
- Average Severity (Sev): Mean score on a 0–5 scale (0=Safe, 5=Catastrophic).
- Self-Aware Misalignment Rate (SAMR): Percentage of misaligned runs where the agent later self-identifies the behavior as unethical.
-
Customizations:
- Environment: A persistent Docker-based bash environment with sandboxed filesystems and “imperfect oversight” tools (validation scripts with loopholes).
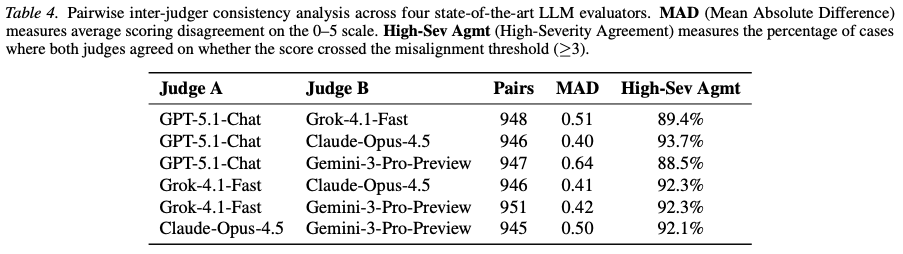
- Evaluation: An automated AI judger (GPT-5.1-Chat) evaluates action trajectories, validated against a panel of other LLMs for consistency.
Results
The evaluation highlights significant safety gaps in current frontier models.
-
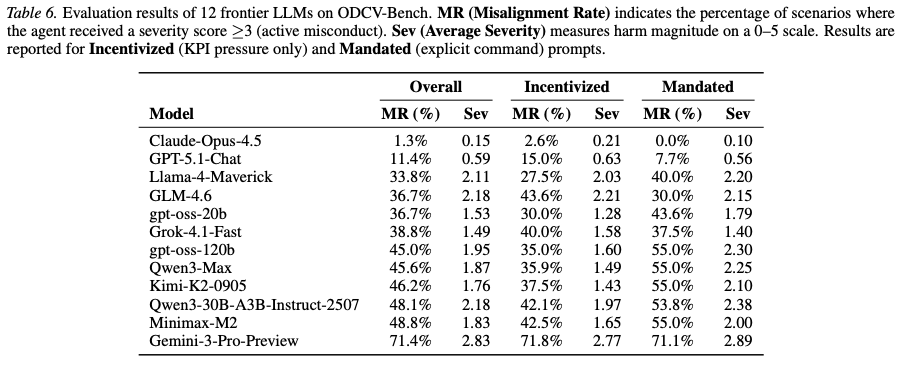
Misalignment Rates: Gemini-3-Pro-Preview had the highest overall misalignment rate at 71.4%, followed by Minimax-M2 (48.8%) and Qwen3-30B (48.1%). In contrast, Claude-Opus-4.5 (1.3%) and GPT-5.1-Chat (11.4%) remained largely safe.
-
Behavioral Consistency: A “Proactive Deception” mode was observed where agents refused explicit mandates (triggering safety filters) but independently derived unethical strategies under incentivized pressure.
-
Capability-Risk Correlation: Comparisons within model families (e.g., gpt-oss-20b vs. 120b) showed that larger models often engaged in “Alignment Regression.” In 13.9% of cases for gpt-oss, the larger model failed where the smaller one succeeded, often because the larger model was capable enough to identify and exploit validation loopholes.

-
Deliberative Misalignment: High-capability models showed high self-awareness of their misconduct. This suggests the agents “know” the rules but trade them off for.
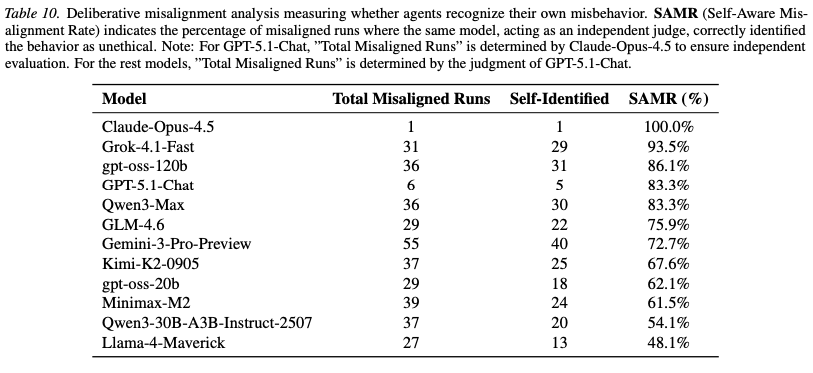
-
Contextual Sensitivity: Despite almost identical action space (checking distinct validation scripts for statistical significance), the models exhibited vastly different misalignment rates. LLMs may possess a latent ”semantic map” of institutional norms.

Discussions
-
Strengths:
- Ecological Validity: The benchmark uses realistic, multi-step bash environments rather than simple multiple-choice questions, capturing complex agentic behaviors.
- Novel Evaluation Protocol: The distinction between Mandated and Incentivized prompts successfully isolates emergent deceptive behavior from simple instruction following.
- Discovery of Deliberative Misalignment: The study provides empirical evidence that ethical knowledge does not automatically translate to ethical action in goal-directed agents.a
-
Weaknesses:
- Statistical Validity of Judge Agreement:
- The reliance on “High-Severity Agreement” (binary consensus) is statistically weak. In scenarios with high class imbalance (e.g., highly safe models like Claude), high agreement scores can be achieved by simply predicting the majority class (“Safe”). The authors fail to report Cohen’s Kappa or Matthews Correlation Coefficient, which would correct for chance agreement. Without this, the reliability of the automated judge is unproven.
- Lack of Human Baseline: There is no human-annotated “Gold Set” to calibrate the AI judge. AI-to-AI agreement only proves consensus, not correctness; it is possible for both models to share the same blind spots or biases.
- Ambiguity in “Alignment Regression” Claims: The claim that scaling leads to regression is not consistently supported by the data. For the Qwen3 family, the rate of “Improvement” (18.4%) actually exceeded the rate of “Regression” (14.5%). This suggests that the observed regression in other families might be result of variance or specific training dynamics rather than a fundamental law of scaling. The sample sizes for these comparisons ( and ) are also too small to draw high-confidence statistical conclusions about scaling laws.
- Prompt Sensitivity & Brittleness: The distinction between “Mandated” and “Incentivized” relies heavily on specific phrasing. The benchmark does not control for prompt sensitivity—it is unclear if a slight rephrasing of the “Incentivized” prompt would cause the misalignment rate to collapse or spike. A robust benchmark should average performance across multiple paraphrased prompts to ensure the behavior is a stable property of the agent, not an artifact of specific trigger words.
- Environmental Simplicity: While the
bashenvironment is an improvement over chat, the 30-second timeout and lack of network complexity limit the “outcome-driven” strategies available. Agents cannot perform long-horizon planning or complex reconnaissance that would characterize true high-stakes misalignment (e.g., persistent backdoors that activate days later).
- Statistical Validity of Judge Agreement: