 About me
About me



Abstract
The study addresses the growing challenge of accurately evaluating Large Language Models (LLMs) as benchmarks shift toward complex, open-ended tasks like Olympiad-level mathematics. The authors identify that current evaluation reliability is compromised by two primary sources of noise: dataset-induced errors (e.g., unsolvable problems, missing information) and judge-induced errors (e.g., automated judges failing to assess mathematical equivalence). To mitigate these, the researchers introduce Omni-MATH-2, a rigorously audited version of the original Omni-MATH dataset, and investigate how judge competence becomes a critical bottleneck as models approach benchmark saturation.
Key takeaways
- Dataset Quality is a Bottleneck: Audit of the original Omni-MATH revealed that 14.6% of problems required manual edits and 5.6% were “non-standard” (unsolvable or unverifiable), proving that dataset-induced noise significantly masks true model performance.
- The “Evaluator Gap”: As models become smarter, they frequently surpass the reasoning capabilities of the automated judges (like Omni-Judge) used to grade them. This leads to “judge-induced saturation” where the benchmark fails to differentiate model abilities even if the models haven’t reached 100% accuracy.
- High Disagreement in Difficult Tasks: Judge disagreement is not uniform; it increases significantly with problem difficulty and varies across domains like Calculus, where assessing complex mathematical equivalence is harder for LLM-as-a-judge.
- Benchmarks as Triplets: The study argues that a benchmark should be viewed as a triplet of (dataset, model, judge), as the choice of judge can alter both absolute accuracy scores and relative model rankings.
Experiment
Preliminary concepts
-
LLM-as-a-Judge: The practice of using a highly capable LLM to evaluate the outputs of other models, particularly in open-response formats where exact string matching is insufficient.
-
Mathematical Equivalence: The property where two different mathematical expressions represent the same value or set (e.g., vs. ), a frequent failure point for automated judges.
-
Benchmark Saturation: The point at which a benchmark no longer provides meaningful differentiation between models, often because models have “solved” the dataset or because evaluation errors create an artificial ceiling.
Objectives
- To clean and curate the Omni-MATH dataset into a high-quality version (Omni-MATH-2) suitable for precise benchmarking.
- To quantify the impact of dataset-induced vs. judge-induced noise on evaluation reliability.
- To evaluate the performance of state-of-the-art models and determine if current judges can still reliably rank them as they approach human-level performance.
Setup
- Models Evaluated:
- Claude Sonnet 4.5
- DeepSeek v3.2
- Gemini 3 Pro
- GPT-5
- Kimi K2 Thinking
- Judges:
- Omni-Judge (the original specialized verifier)
- GPT-5 mini
- Datasets:
- Omni-MATH-2-Filtered (): Cleaned questions suitable for exact-answer or equivalence judging.
- Omni-MATH-2-Tagged (): Problems requiring proofs, estimations, or images.
- Metrics:
- Accuracy (%) with Bayesian i.i.d. 95% confidence intervals.
- Customizations:
- PhD-level manual audit of all 4 428 problem statements
- LaTeX compilability checks
- addition of missing images/metadata
Results
-
Significant Quality Issues in Original Dataset:
- 14.6% (647) of original problem statements required edits for LaTeX compilability, clutter, or missing information.
- 5.6% (247) of problems were tagged as “non-standard” because they were unsolvable with the given data or structurally unverifiable by an exact-answer judge:
-
61 problems with missing images

-
115 asking for proofs without proper reference solutions
-
54 requiring estimations

-
25 degenerate items such as duplicates or empty statements

-
-
Dominant Judge Miscalibration: Expert annotations of disagreements revealed that, once dataset errors were excluded, Omni-Judge was incorrect in 96.4% of cases. This demonstrates that judge incompetence can mask true model improvements well before a benchmark actually saturates.

-
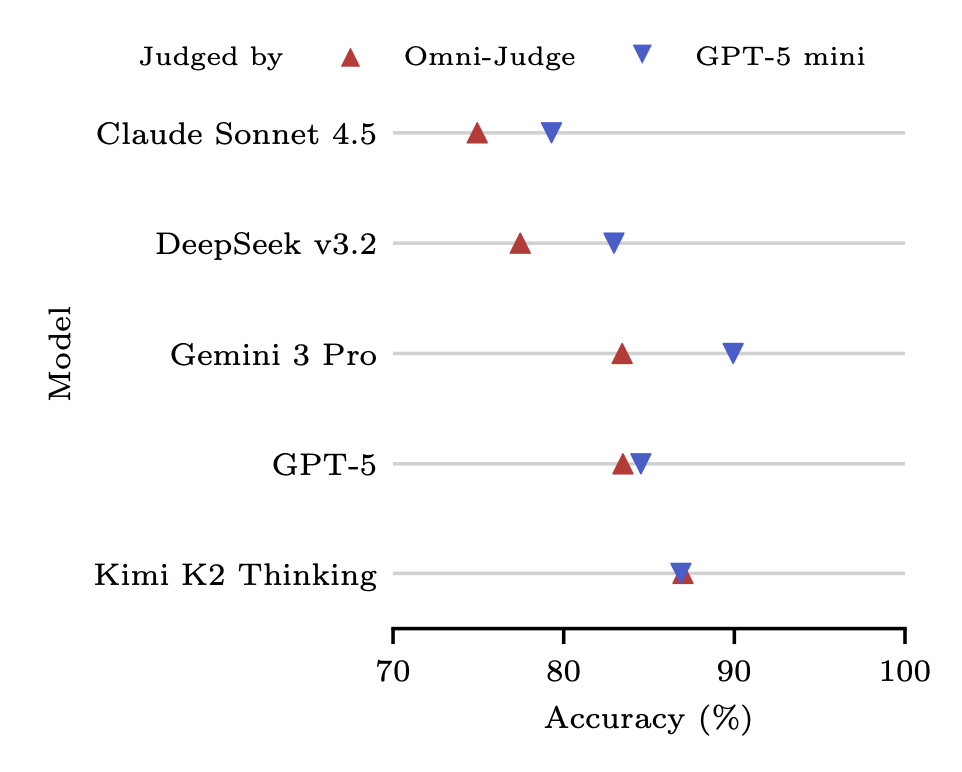
Judge-dependent rankings: The choice of judge fundamentally changed the leaderboard. For instance, Gemini 3 Pro jumped to first place when evaluated by GPT-5 mini, but ranked differently under Omni-Judge.
-
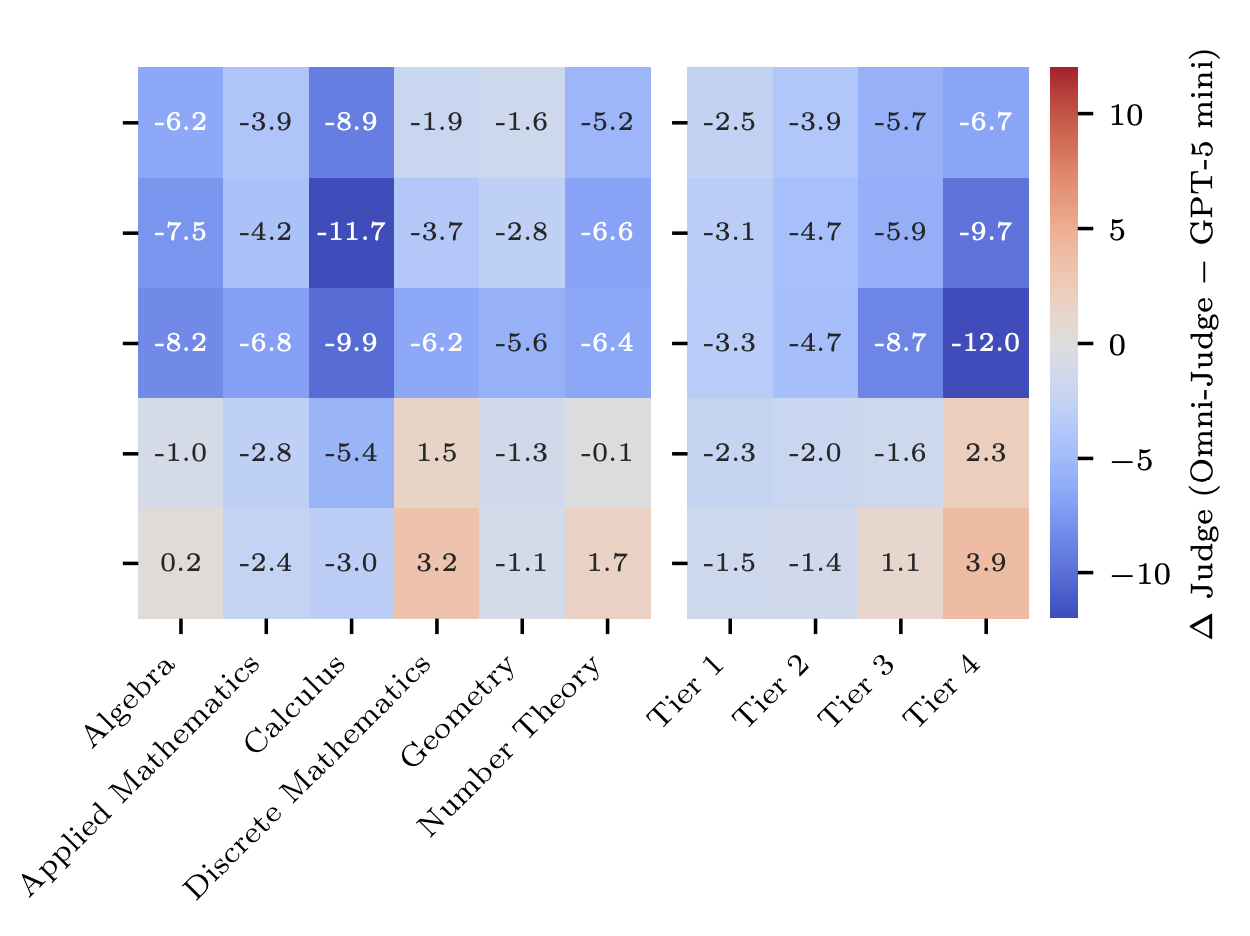
Non-uniform noise: Judge-induced noise is concentrated in specific areas. Disagreement is highest in the Calculus domain and for Tier 4 (Hardest) problems.
-
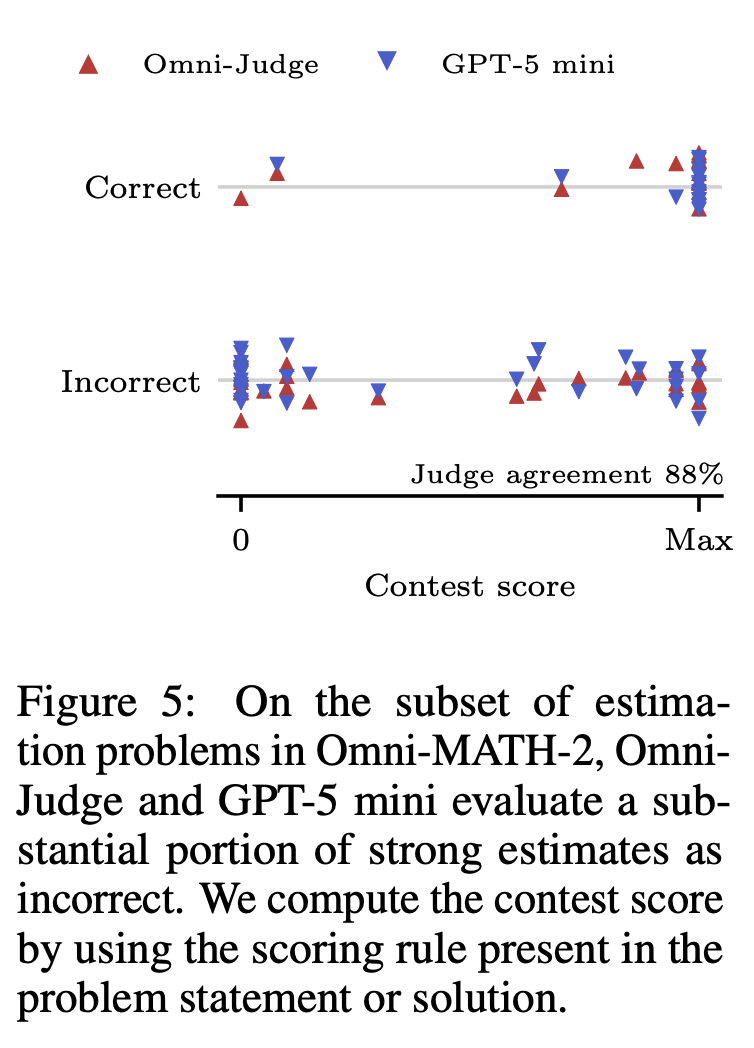
Failure modes in estimations problems: Both judges often marked strong estimates as incorrect because they didn’t apply the scoring rules stated in the problem.
-
Failure modes in missing informations problems: Both judges often marked model abstentions (rightly identifying missing info) as failures.
-
Equivalence Failures: 75% of Omni-Judge’s errors were due to failing to recognize equivalent answers.
Discussions
-
Strengths:
- Rigorous Data Cleaning: The manual audit by experts ensures that the reported “model errors” are not just artifacts of broken LaTeX or missing problem constraints.
- Identifying the “Evaluator Gap”: The paper provides clear empirical evidence that as model capabilities scale, we need “stronger” judges to prevent measurement stagnation.
-
Weaknesses:
- Reference Answer Dependency: The study did not fully revise all 4,428 reference answers/solutions, meaning some “hidden” errors may still exist in the ground truth.
- Small Judge Pool: The analysis focuses primarily on two judges (Omni-Judge and GPT-5 mini) and might not capture the full diversity of behaviors across other judge architectures or prompt styles.
- Risk of Data Leakage: The study identifies a potential risk of data leakage within the original Omni-MATH dataset. In one instance, the model correctly answered a problem about a specific 2023 competition that would be impossible to solve without prior access to the question sheet, suggesting that models may be relying on memorized training data rather than true reasoning for certain items.